Summary: Intro | Virtualisation Software | Cloudera’s QuickStart VM | Importing a VM
In this post, I will introduce Virtual Machines: the core platform of every data scientist. If you, like me, get to experiment with different technologies at work, you are familiar with Virtual Machines. VMs are the best way of getting to test something out without having to install it on your computer and risking messing up your working environment. In its essence, a VM is like a mini (virtual!) computer you put on your computer; that computer has its own environment, like Windows, Linux or MacOS, and it would usually come with a bunch of pre-installed and configured tools, so that you don’t have too worry about any (or much) setup. So you might have a Windows machine installed on your actual Windows machine, and while these two share computing resources and space, they are separate instances of Windows. Plus, the virtual machine you can delete or change as you please, you can have many and, by definition, this has no impact on your original working environment.
Many technology vendors provide VMs with their software as a marketing channel: they want to get you test their stuff (and, ultimately, buy), without having you fed up with the setup. It’s often worth checking out the download section of a software provider you’re interested in, just to see if they have a box ready for you to put on your computer.
I was studying a combined business & IT degree, but while we worked with databases, we have never been introduced to Virtual Machines. It wasn’t until I did an online course that required getting a VM setup, and along the way having some software screw up my computer, that I understood the usefulness of VMs myself. At my first job in IT I would use VMs in a “follow the instructions and click on where they tell you” mode. Then I moved jobs, and the new role of a consultant required I treat VMs as my best friend: with respect but also with profound understanding.
I looked back to that days to come up with some guidelines on working with VMs for a newcomer to data science. If you want to play with any big data technology, you will get to use VMs all the time. On this blog, I plan to go through a number of IT vendors to show you what they offer. First things first, though: let’s get our first machine on the computer to see how it’s done!
Getting virtualisation software
Before you get a Virtual Machine on your computer, you need to install virtualisation software that will allow you to manage your machines. That includes importing these environments from their raw file, starting them up and closing, setting their storage and computing power allowance, specifying the way they contact the web and your mother machine. There is a number of vendors that distribute VM managers for free for personal use. Two of them – perhaps the most popular ones – are VMWare and Oracle’s Virtual Box. I used both and both of them are great. They support all main operational systems. I will be using VirtualBox in this blog as I already have it on my computer, but feel free to choose either.
Download and install VirtualBox from Oracle’s official website. Choose the version dedicated for you OS. Get and install the Extension Pack too.
While the software is being installed you can proceed to the next section.
Getting a Virtual Machine image: Cloudera’s QuickStart VM
The machine I chose for the first project is Cloudera’s Quick Start VM. It is a Linux box with their own distribution of Apache Hadoop and dedicated tools. It’s a perfect starting point for any data scientist and I will be using this machine as my primary environment for many projects to come. I will talk about Cloudera and what’s included in their VM in the upcoming post.
You get your copy of Cloudera’s VM from their downloads website
The image version you download has to be supported by your virtualisation software. In my case I had to pick Virtual Box. The website then asks you to fill out a short questionnaire and the automatic download begins.
The download will take a while depending on your internet connection, as it’s a 5GB file. Note that on the download page there is a list of requirements your computer should fulfill to get Cloudera’s image running. Their QuickStart option calls for 4GB of RAM, so it should be supportable by most personal computers. The more memory you allocate to the machine, the faster some processes will run, and I’ll show you how to do it in the next section.
The downloaded file is a zip package. Unzip it with 7Zip or another archive manager.
Importing a VM
Open up your VirtualBox or another virtualisation software you decided to use. There’s one setup step I wanted to talk about before we get to importing the Cloudera’s machine. This should be relevant for any virtualisation software – here I am using VirtualBox to illustrate the process.
If there is one thing you should setup before starting to use your VirtualBox, it is the folder where the manager stores imported VM images. Choose a location on disk where you’ve got plenty of free space: for Cloudera’s VM you require at least 5GB of space. In VirtualBox you specify the folder by going to File > Preferences > General.
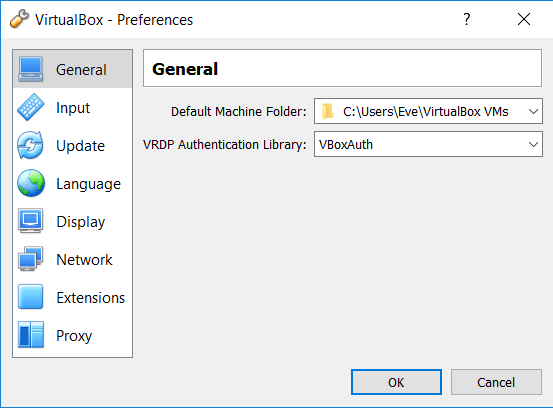
Hit OK to save your preferences. Now we’re ready to import the VM.
Go to File > Import Appliance and navigate to the unzipped Cloudera’s VM folder.
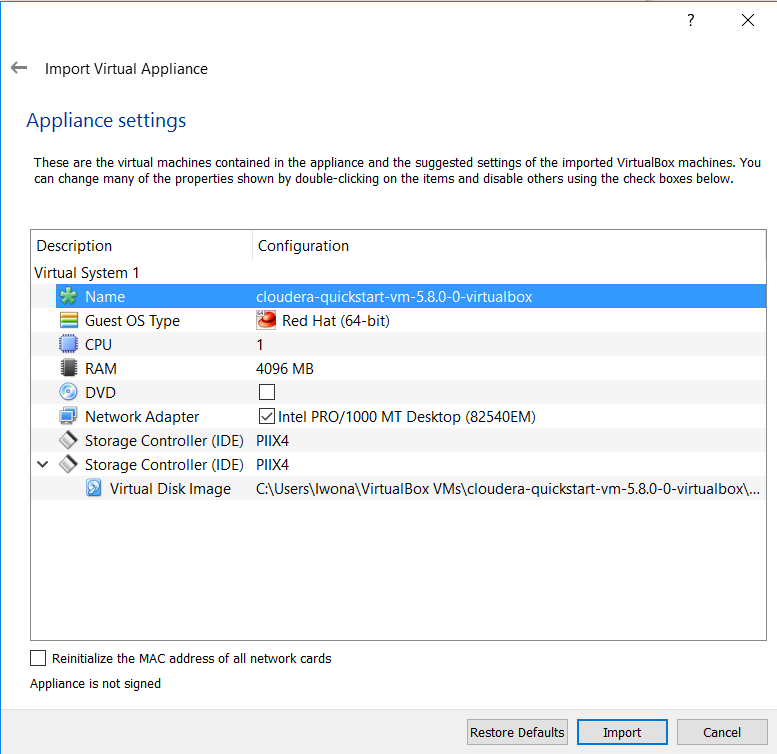
Select the .ovf file. The next screen will display the default VM settings (Cloudera’s recommendation). For now it’s okay if you just accept the defaults. The machine will take a few minutes to import.
Before you start the virtual machine I recommend you check the memory available on your computer and that you close any application that’s eating up your resources. You can check that in the task manager of your OS. Even a few opened browser windows can be memory consuming, so try keeping these to minimum. I, for one, have a tendency to open as much browser windows as my screen can take, so I need to remind myself of this constantly. The VM is quite resource consuming and it might pause, or even crash if it doesn’t get the required 4GB of memory.
We’re done with the initial setup. In the next post I plan to go through VM networking. I hope the post has been useful – any comments or suggestions are very welcomed.
Eve the Analyst
Follow @EveTheAnalyst